Key Features:
- A new AGI benchmark reveals that today’s most advanced AI models still fall short of artificial general intelligence.
- The ARC-AGI-1 dataset, now five years old, continues to challenge AI systems with abstract, high-level reasoning tasks.
- Even top AI models from platforms like OpenAI, Google, and Hugging Face AI showed inconsistent results.
- Tools like Gizmo AI and Quillbot AI perform well in narrow tasks but lack AGI-level flexibility.
- ARC-AGI-1 exposes a critical gap in how we check for AI intelligence across different use cases.
- The AGI test challenges the way we measure intelligence, urging the industry to develop AI that can generalize knowledge rather than just perform.
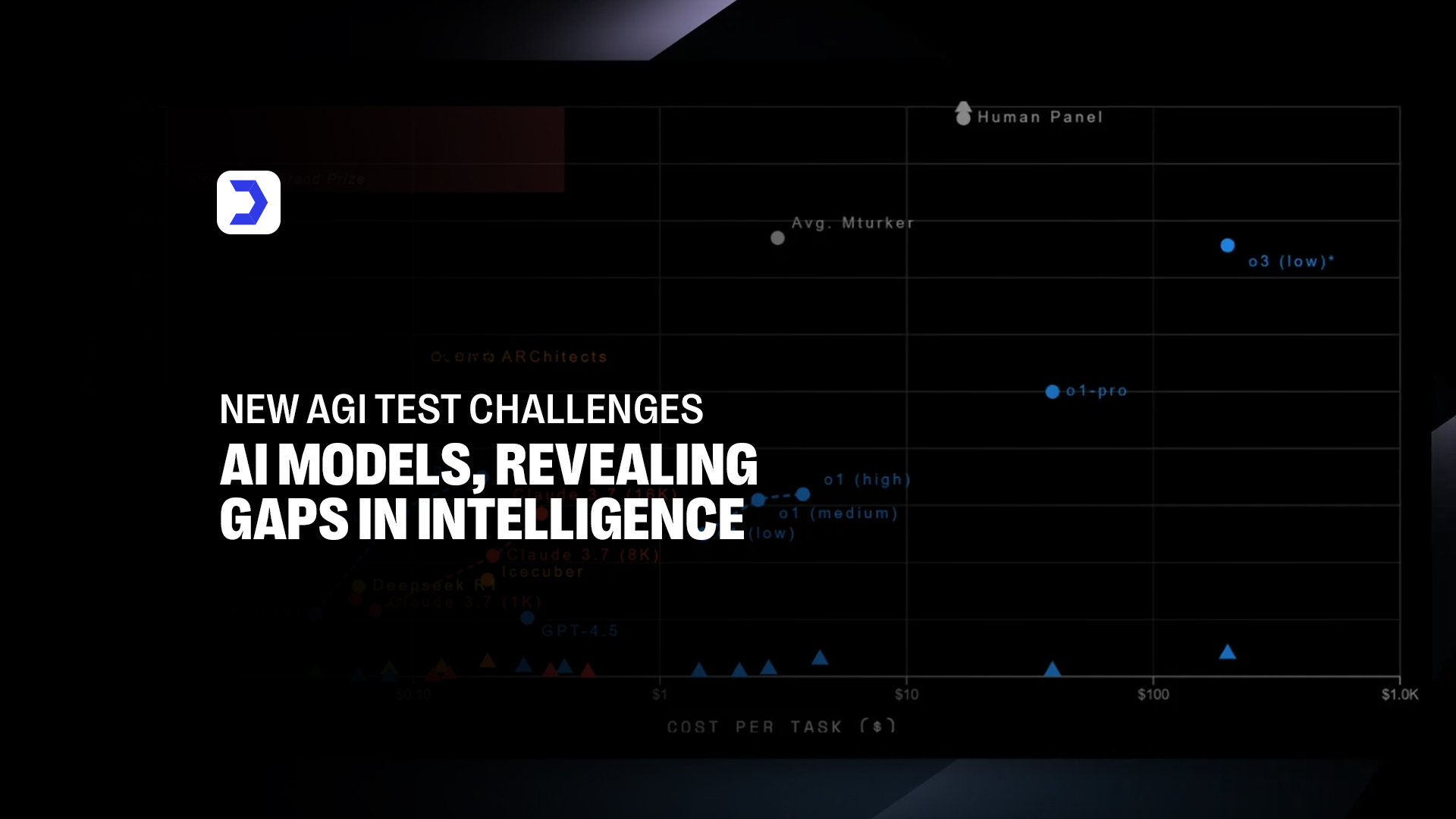
A newly developed benchmark for artificial general intelligence (AGI) is shaking up the AI industry, putting even the most advanced AI models to the test. The AGI evaluation, recently introduced and examined by researchers, reveals surprising weaknesses in how today’s top AI models handle reasoning, logic, and real-world problem-solving. The AI test, which was designed to measure higher-order cognitive ability, has proven that while many AI systems excel at specific tasks, they still struggle with general intelligence, the hallmark goal of AGI.
TechCrunch reports that the test stumped several leading models from platforms like OpenAI, Google, and Hugging Face AI. The surprising results prompt researchers to rethink how we evaluate intelligence in artificial systems. Despite high AI scores in standard benchmarks, the new AGI test challenges those metrics by introducing complex, abstract questions that require more than just pattern recognition.
This performance gap underscores the current limitations of even the top AI models. Systems previously thought to be approaching AGI-level capability performed inconsistently, revealing significant gaps in understanding, adaptability, and reasoning. It’s a stark reminder that while AI tools are becoming more powerful, artificial general intelligence remains elusive.
As the AI race intensifies, businesses and developers are closely monitoring how different models perform under pressure. Digital Software Labs has followed this evolution in their recent roundup of the hottest AI models right now, showing how AI scores vary between tasks and confirming that no current model has mastered AGI-level thinking. These findings further validate that even highly refined systems lack the general adaptability that true AGI demands.
ARC-AGI-1 Dataset Turns Five
The ARC-AGI-1 dataset, the foundation for the new AGI test, has reached its five-year milestone and continues to challenge the very best. This upgraded version of the Abstraction and Reasoning Corpus aims to push the boundaries of AI models by testing their abilities to think abstractly, create original solutions, and reason through unfamiliar problems.
Platforms across the spectrum, including OpenAI, Google AGI initiatives, and frameworks hosted by Hugging Face AI, have run their models through ARC-AGI-1. Despite these platforms achieving remarkable results in natural language tasks, their models failed to show consistent performance across ARC’s problem-solving metrics. This raises critical concerns about how we check AI systems for actual intelligence versus performance optimization.
Evaluators noted that even highly capable systems, including GPT-powered platforms and modern Skype models, struggled to achieve high AI scores on this dataset. That inconsistency highlights how much more development is needed before we can confidently claim to have reached artificial general intelligence.
This shift in intelligence benchmarking is reshaping how we evaluate and check for AI readiness. For example, Gizmo AI, reviewed by Digital Software Labs, excelled in specific task automation but lacked the reasoning scope ARC-AGI-1 demands. Similarly, the platform’s review of Quillbot AI revealed exceptional performance in targeted rewriting, but like many AI systems today, it showed limitations in learning abstract rules without prior context.
Digital Software Labs continues to provide critical industry insight through AI reviews, such as Gizmo AI and Quillbot, and coverage in its news section.
These insights demonstrate the growing gap between narrow AI functionality and the holistic intelligence that AGI aspires to achieve. As these tests gain traction, developers are being challenged to build not just smarter models but models that understand.